
You inherit a three-brand phone estate one decision at a time. Head office standardized on Cisco CallManager years ago. The branch you acquired in 2021 came with an Avaya IP Office that works fine, so it stayed. The warehouse runs a Panasonic that was installed before anyone in IT was hired and refuses to die. Each system does its job. The estate as a whole is a blind spot, because the one person who can say how the company answered its phones yesterday has to log into three tools to find out, and in practice that round of logins loses to whatever else is on fire.
If you manage telecom for an organization like this, three working PBXs are an asset, and rip-and-replace would spend capital to fix a reporting problem. The goal is one screen that treats them as one phone system.
Per-site tools do not add up to a picture
Each PBX ships with some reporting of its own, and at one site it may be enough. Across sites, three problems compound.
No comparison. Cisco CDR reports and Avaya SMDR summaries do not share definitions, formats, or even time conventions. The branch manager says “our phones are slammed,” HQ says “ours too,” and you have no common ruler to check either claim against.
No roll-up. A question as basic as “how many calls did the company miss last week?” becomes an export-and-spreadsheet project. Most months the project stays on the someday list, and the question waits until a customer complaint forces it.
N logins, N skill sets. The admin who reads CallManager reports has no idea where the Panasonic maintenance console lives. Reporting knowledge stays trapped per site, and when the one admin who understood the warehouse system leaves, that site goes dark.
The result: you manage the site with the best tooling and assume the rest.
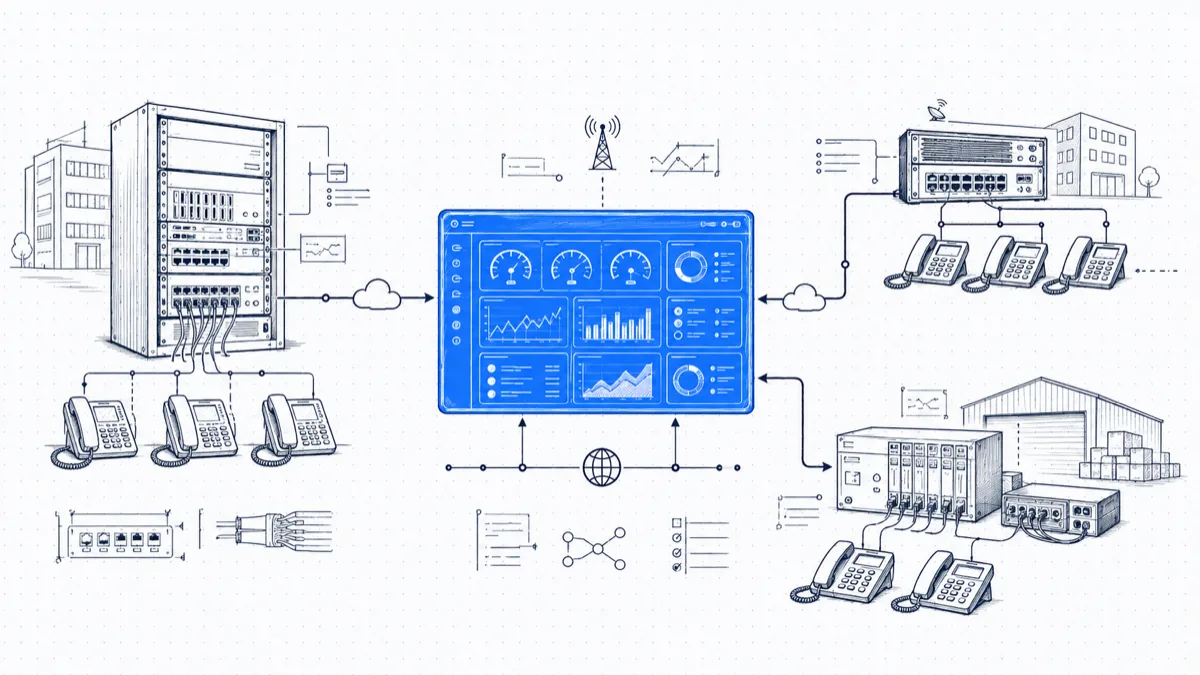
The architecture: a collector at each site, one account in the cloud
The structure that fixes this is simpler than most monitoring deployments. Each PBX already emits call records (CDR on some brands, SMDR on others) over a serial port, an IP connection, or as files. At each site, a small collector app installed on any always-on Windows machine reads that local output and streams it over TLS to one cloud account for your organization. Fifteen minutes per site is a realistic install estimate, and the collector does not care how old the PBX is; if the system writes call records, end-of-life models included, the collector can read them.
A few deployment notes from the field:
- The collector machine needs outbound HTTPS only, the same access a browser already has; inbound ports, site-to-site VPNs, and extra firewall exceptions stay closed.
- One collector handles one site’s PBX; sites with two systems (a Cisco for offices and an Asterisk for the call center, say) run two connections.
- Tag each collector with its site name on day one. Each view described below depends on that label.
- Check the clocks. Cross-site hourly views are only as honest as the timestamps behind them, so point each PBX at an NTP source where the system supports it, and confirm the platform records each site’s local timezone. A heatmap that compares one site logging in UTC against another logging local time will invent phantom peaks.
The supported-systems list covers the usual suspects in mixed estates: Cisco, Avaya, Mitel, Panasonic, 3CX, and Asterisk/FreePBX.
Normalizing metrics across brands
Normalization is what makes cross-site comparison honest. A Cisco CDR and a Panasonic SMDR line look nothing alike, but both contain the same facts: the call’s start time, its ring duration, who answered or did not, the talk time, and the trunk that carried it. Once each record is parsed into a common model, a missed call is a missed call, whether the PBX that logged it cost $40,000 or came out of a closet.
That common model lets you put “answer rate by site” on one chart without an asterisk under it. Check, whatever tool you use, that the definitions align: ring time measured the same way, internal calls excluded the same way, transfers counted once. If two sites differ by a point or two of answer rate, the gap should trace back to the people answering, with both parsers measuring the same way.
The cross-site views that earn their place
We have watched a lot of multi-site deployments settle in, and four views do most of the work.
Answer rate by location. The single most-watched widget. One bar per site, this week against last. It converts “we think the branch struggles” into “the branch answers 81 percent against a company average of 93.”
Traffic by location and hour. A heatmap of offered calls per site per hour exposes how different the sites’ days run. Warehouses spike at 7 a.m., sales offices at 10. The heatmap is also where you discover that one site’s “understaffing” is a two-hour surge each day, hidden inside the company-wide average.
911 events, anywhere. With all sites feeding one account, a 911 call at any office can alert both the local front desk and the central safety contact within a minute or two. For a multi-site company this is the difference between per-site compliance and knowing it happened.
Trunk utilization per site. Sites buy trunks on history and gut feel. A per-site peak-utilization view shows the branch paying for 23 channels and leaving 9 of them idle, and the office that hits 100 percent on Monday mornings and bounces callers to busy signals. Both numbers are money.
Spotting the underperforming branch
One pattern comes up often enough to describe from memory. Company average answer rate: 92 percent. Branch X: 84. Before the roll-up existed, that gap was invisible; the branch’s own monthly report showed “calls handled: 1,840,” which sounds like work getting done. The hourly heatmap then shows the misses cluster between 12:00 and 14:00: overall staffing is fine, and a lunch rotation empties the desk for two hours. The fix costs nothing. The cross-site comparison gave you the trigger to look, the hourly breakdown gave you the diagnosis, and you walk into the branch manager’s office with data and a question.
Local managers see their site, you see all of them
A roll-up dashboard fails on office politics if the branch manager inside it has no access to her own numbers. Give each site’s manager a login scoped to their location: their dashboards, their reports and alerts, and no other site’s traffic to misread out of context. Telecom and leadership keep the all-sites view. In practice this also distributes the watching: local managers catch their own anomalies within a day, and the central team stops carrying the news for each dip.
Where PBXDom fits
This deployment shaped PBXDom: one collector per site feeding one cloud account, mixed Cisco, Avaya, Mitel, Panasonic, 3CX, and Asterisk/FreePBX estates normalized into the same dashboards, site-scoped logins for local managers, and 911 alerts from any location. The 14-day trial is enough to bring two or three sites online and put answer rate by location on one screen for the first time; start with onboarding.